孤独不孤独

你听说过孤独症吗?
当你听到“孤独症”时,会想到什么?《雨人》中那个看起来有些迟钝,却拥有超常记忆力的天才?《良医》中那个逻辑精准、情感冷静、仿佛“自带算法”的呆萌医生?还是影视作品里常出现的,几乎无法与外界沟通,需要被完全照顾的孩子?其实这些画面并非凭空出现,它们来自大众文化对孤独症的反复演绎。但问题在于,这些形象其实只覆盖了这个群体极小的一部分,也忽略了更多真实而复杂的日常。
孤独症的全称是孤独症谱系障碍(Autism Spectrum Disorder,ASD)。“谱系”这个词意味着:孤独症不是一种单一的状态,而是一整条的连续光谱。在这条光谱上,有人语言表达流畅,有人几乎不说话;有人可以独立生活,有人则需要长期支持;也有人在某些领域表现突出,却在日常互动中感到困难。但无论差异有多大,孤独症群体往往共享一些底层体验。比如,对信息的理解方式与常人不同。很多孤独症个体在面对复杂、模糊或快速变化的信息时,会更容易感到压力。他们可能不擅长从一句话中推断出话外余音,也不容易通过表情、语气或场景变化,快速理解他人的意图。
这些特点在孤独症个体的成长阶段中,往往会被进一步放大。在孤独症儿童的学习和成长中,他们除了学习书本知识之外,还需要在特殊帮助下学会理解社交规则、情境、情绪。在他们的学习过程中,需要具有稳定、结构清晰、可以被反复理解特点的学习材料。表达方式频繁变化的材料内容,反而可能成为额外的干扰。在这样的背景下,对于孤独症儿童的教育材料,“用什么样的方式去讲清楚一件事”,变成了一个非常现实、具体的问题。
需要被反复讲清楚的事情
在很多孤独症儿童的学习过程中,最难的往往不是“学不会”,而是需要被用更清晰、更一致、更可重复的方式讲明白。尤其是社交相关的内容,比如表达感谢、拒绝、理解他人的情绪、在不同场景下该怎么回应,这些对多数孩子来说是“自然习得”,但对不少 ASD 儿童来说,更像是一门需要反复拆解、练习、复盘的“课程”。正因如此,传统特教其实已经形成了一套很成熟的方法体系:结构化课堂、视觉提示卡(提示步骤/规则/情绪)、情景演练、奖励机制、家庭协同等等。它们有效,但也有一个现实瓶颈:高度依赖一线老师的讲解与定制以及家长的配合。同一个知识点,可能需要老师换三种说法、做五次演练,才能让孩子在真实场景里用得出来;同一个班的不同孩子,可能又需要完全不同的材料和节奏。于是人工成本被不断推高,一线特教老师长期处在“既要教、又要哄、还要随时调整方案”的高压状态,机构端也很难把这种高质量支持规模化复制。
在这样的背景下,绘本就显得格外有价值。它的优势在于:结构清晰、情境具体、表达直观、可反复阅读。每次翻开都是一致的逻辑、一致的情绪线索、一致的因果关系。孩子可以在安全、可控的节奏里反复练习理解:这个场景发生了什么?角色为什么这样做?我遇到类似情况应该怎么表达?但因为孤独症儿童“千人千面”的特点,同样是“谢谢”,有的孩子需要更夸张的表情提示,有的孩子对表情不敏感,更依赖动作或语言;同样是“拒绝”,有的孩子需要非常具体的句式模板,有的孩子需要先处理情绪再进入沟通;同样的画面密度、色彩刺激、人物互动强度,对不同孩子的效果也可能完全相反。这导致市面上的绘本难以满足对于孤孤独症儿童的教育需求。而一旦走向定制化绘本,制作成本就会急剧上升,不仅是写故事、画插图的成本,更是反复调整、验证、迭代的成本。这对家庭来说很难持续承担;对机构来说也难以规模化生产与维护。
LLM是否是问题的答案?
从表面上看,AI 似乎正好站在这个问题的正中央。一方面,它几乎天然地解决了“规模化”的问题。只需要一条prompt就能生成对应的插图,生成内容的边际成本够低;另一方面,AI 又擅长根据输入query进行变化,看起来也非常适合应对 ASD 儿童“千人千面”的个体差异。似乎LLM 既能降本,也能定制化,这几乎正中需求。乍一看LLM像是问题的“标准答案”。但真正的问题,恰恰藏在这里。LLM 的本质,并不是“理解”,而是基于大量训练数据,对下一步最可能出现的结果进行预测。这意味着,每一次生成,哪怕输入看起来完全相同,背后都存在着一定程度的不确定性。在图像生成的场景下,差异可能体现在:构图、色彩、场景元素、人物形象。对大多数普通用户来说,这些变化往往只是体验上的差异,甚至还会被理解为“多样性”或“创造力”。但在面向孤独症儿童的场景中,这些不确定性却可能变成一种干扰,甚至是一种风险。当同一个角色在不同页面里悄悄变了衣服、表情或比例,当画面中多出或少了某些不重要却显眼的元素,当情绪表达方式在无意中发生偏移,这些变化都会直接影响孩子对情境的理解、反应。于是在这个场景下,真正的问题是:如何在保证稳定性的前提下,利用LLM/AI来完成孤独症儿童绘本的制作?
小有可为
上述的背景与问题,正是由阿里巴巴魔搭社区与南京特殊教育师范学校共同发起的“小有可为”AI 开源公益创新挑战赛。这项比赛并不只是一个简单的技术竞赛,而是直接围绕现实中的社会问题展开设题,旨在推动 AI 技术与公益场景之间的深度结合。其中一个重点赛题是 “追星星的 AI:孤独症儿童绘本 LoRA 训练挑战”,要求参赛团队在魔搭社区开源生态下,基于现有模型与工具,微调 LoRA 风格模型,以生成适合孤独症儿童的绘本内容。这项赛事并不鼓励单纯的技术炫技,而是希望参赛者基于平台上的 LoRA 风格模型微调能力,探索 AI 在真实公益场景中的可行性与边界。其中我们的队伍(我和一位设计背景的朋友)所设计的技术方案在上百支团队中脱颖而出,并在决赛路演中获得了 “开源贡献奖”。

但其实在刚接触这个问题时,我们并没有急于进入模型训练和微调阶段,而是选择先把问题拆得更清楚一些:
1. 什么样的绘本对孤独症儿童来说是“可用的”?
2. 哪些变化是必要的,哪些变化反而需要被刻意规避?
3.是否存在一种技术路径或整体架构,能够在保留定制化空间的同时,最大程度地收敛不确定性?
在这样的思考下,我们开始尝试寻找一套能够解答上述问题的技术解决方案。接下来要介绍的设计与实现,都是围绕这一核心判断逐步展开的。
第一步,不是训练模型
在前面我们反复提到一个关键词 - 稳定性。但真正落到绘本生成时,这个“稳定”究竟指的是什么?是画风要稳定吗?是构图不能跳变吗?还是人物、场景、表达方式都要尽量可预期?为了解答这个问题我们提出了一个模型概念 - 绘图生成二维矩阵。
这个矩阵的两个维度分别是:
- 功能目标:这本绘本“要教什么”
比如是社交礼仪、情绪认知,还是生活自理能力; - 风格类别:这本绘本“应该用什么方式教”
比如是单页静态呈现、分步引导,还是情绪提示型表达。
两个维度的分类划分参考了学术资料,以及专业特教老师的指导建议。二维矩阵中的每一个矩阵点都是一个具体的LoRA风格模型,这意味着在方案中,我们是对于每个“功能 x 风格”的组合都训练了一个对应的LoRA模型,而非利用一个LoRA模型来应对所有不同风格/功能的绘本场景。

有了“绘图二维矩阵”,当我们面对一个新的故事需求时,第一步并不是写 Prompt 或调参数,而是可以根据故事的属性将其映射到我们二维矩阵上的一个坐标点中。举个例子 - 《洗手》:
"乐乐吃完饼干,手上都是饼干屑。"
"妈妈说:‘吃饭前后要洗手,这样才卫生。"
"乐乐走到洗手池边,打开水龙头,挤出洗手液,搓出泡泡。"
"他认真洗手指缝,用清水冲干净,再用毛巾擦干。"
"乐乐看着干净的小手,开心地笑了。"通过二维矩阵,我们会很明确地把《洗手》归类到:
- 功能目标:自理能力 - 帮助孩子学习生活流程、培养独立能力
- 风格类别:常识认知 - 简单,写实,单页,中心对称,高饱和度
于是,这个故事就被映射到了矩阵中的一个具体“点位”,而这个点位,对应的正是一个已经完成微调训练的LoRA 风格模型。这让我们进行绘本制作之间可以回答三个关键问题:
- 这套绘本是教什么的?
- 它应该用什么方式来教?
- 哪些“功能 × 风格”的组合,是值得被稳定复用的?
当这些问题被回答后,模型要做的事情就不再是“自由发挥”,而是在一个被严格限定的空间内,完成可控、稳定、可重复的输出。也正是在这个意义上,我们的第一步,不是训练模型,而是先让问题本身变得确定。
该死的不确定性
我们通过“二维矩阵”解决了:如何快速、稳定地找到一个合适的 LoRA 风格模型。但紧接着,一个更现实的问题随之而来:这些 LoRA 风格模型,本身是如何训练出来的?在训练和实际生成绘本的过程中,那些“不稳定”的结果又是从哪里产生的?如果不回答这些问题,所谓的“稳定生成”只是一句口号。
因此,在进入具体实现之前,我们需要先定位不确定性的来源。在我们的系统中,不确定性并不是随机出现的。它来自几个非常明确的环节。我们将不确定性从源头上定位到三个层面:系统层、输入层、输出层。接下来我们来逐一拆解每个层级。
系统层:在一切开始之前,先收紧生成空间
系统层指的是在训练和生成开始之前,就已经确定的一组先验约束。在这一层,我们关注的不是“模型怎么画”,而是更宏观的问题:我们到底允许它画成什么样?具体来说,系统层承担了两个核心作用:
- 明确绘本的功能目标与风格边界
- 从源头收敛模型的生成空间
系统层的核心流程包括三件事:
- 通过二维矩阵定位绘本类型
我们首先根据绘本的教学目标(如常识认知、自理能力、情绪理解等)和风格类别,对绘本进行明确定位,确定它在矩阵中的位置。 - 在现实世界中寻找参照物
对于每一个矩阵点,我们都会去寻找现实中已经被验证过、在风格和功能上相近的绘本或视觉作品,作为参考样本。 - 锁定绘本的整体风格约束
这些参考并不是为了“模仿”,而是用来明确边界:哪些构图、配色、人物表现方式是被允许的,哪些是需要避免的。
通过系统层的约束,我们做了件很“保守”的事情:尽可能提前决定“该发生什么”,而不是指望模型在生成时临场发挥。

输入层:在训练之前,先消解歧义
如果说系统层解决的是“画成什么样”,那么输入层解决的,就是“模型到底看到了什么”。输入层主要涵盖两个部分:训练数据集的准备 和 数据标注。
训练数据集的准备
在训练数据准备阶段,我们严格沿用系统层已经确定的绘本风格。
具体做法是:
- 将一个完整的故事,按照情节拆分为多个独立、清晰的场景
- 针对每一个场景,生成 3–5 张图片
- 确保这些图片在人物姿态、构图、场景细节上存在细微差异
这样做的目的并不是追求“多样性”,而是提升 LoRA 风格模型的泛化能力与鲁棒性。让模型需要学会的是一种稳定的风格表达,而不是记住某一张具体的画面。同时,在生成这些训练图片时,我们统一采用结构化的 Prompt 范式(如画面风格、主体、背景、整体氛围等),并完整保留所有生成 Prompt,为后续流程提供可追溯的上下文。

数据标注
在数据标注阶段,我们利用一个独立的LLM作为我们的标注助手。输入給助手的信息包括:我们利用魔搭社区AI自动打标对训练图片的标注信息,上个步骤留存的Prompt信息。这两个信息虽然都是对于训练图片的描述,但前者侧重“生成图片长啥样”,后者强调“图片是咋生成的”。将两者一同输入給LLM标注助手可以方便助手从不同角度来理解图片。我们的助手根据我们利用Prompt Engineering设定的角色扮演规则 以及 标注范式,生成约束条件进行 图片标注,我们从而获得所需的标注信息。
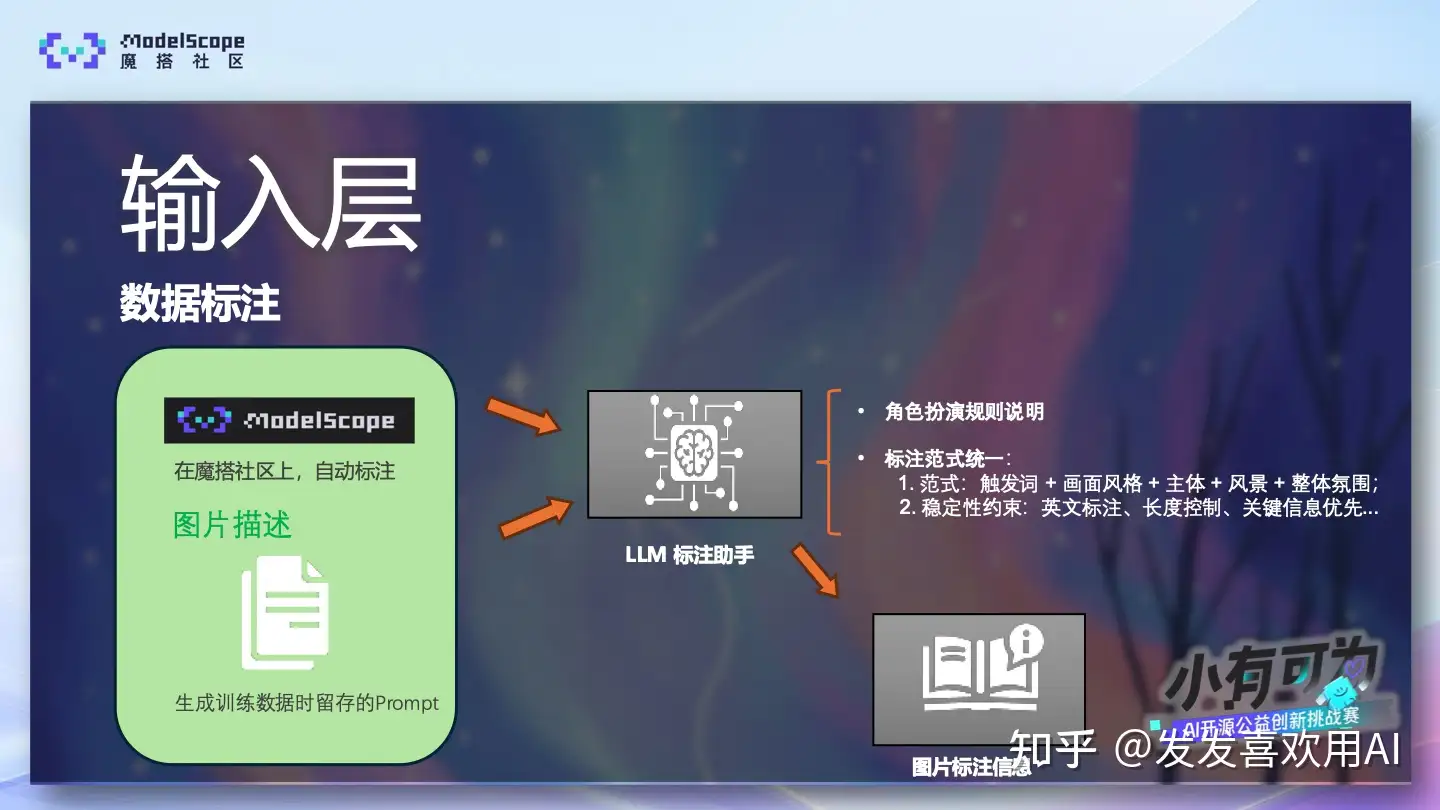
输出层:在生成阶段,最后一道“闸门”
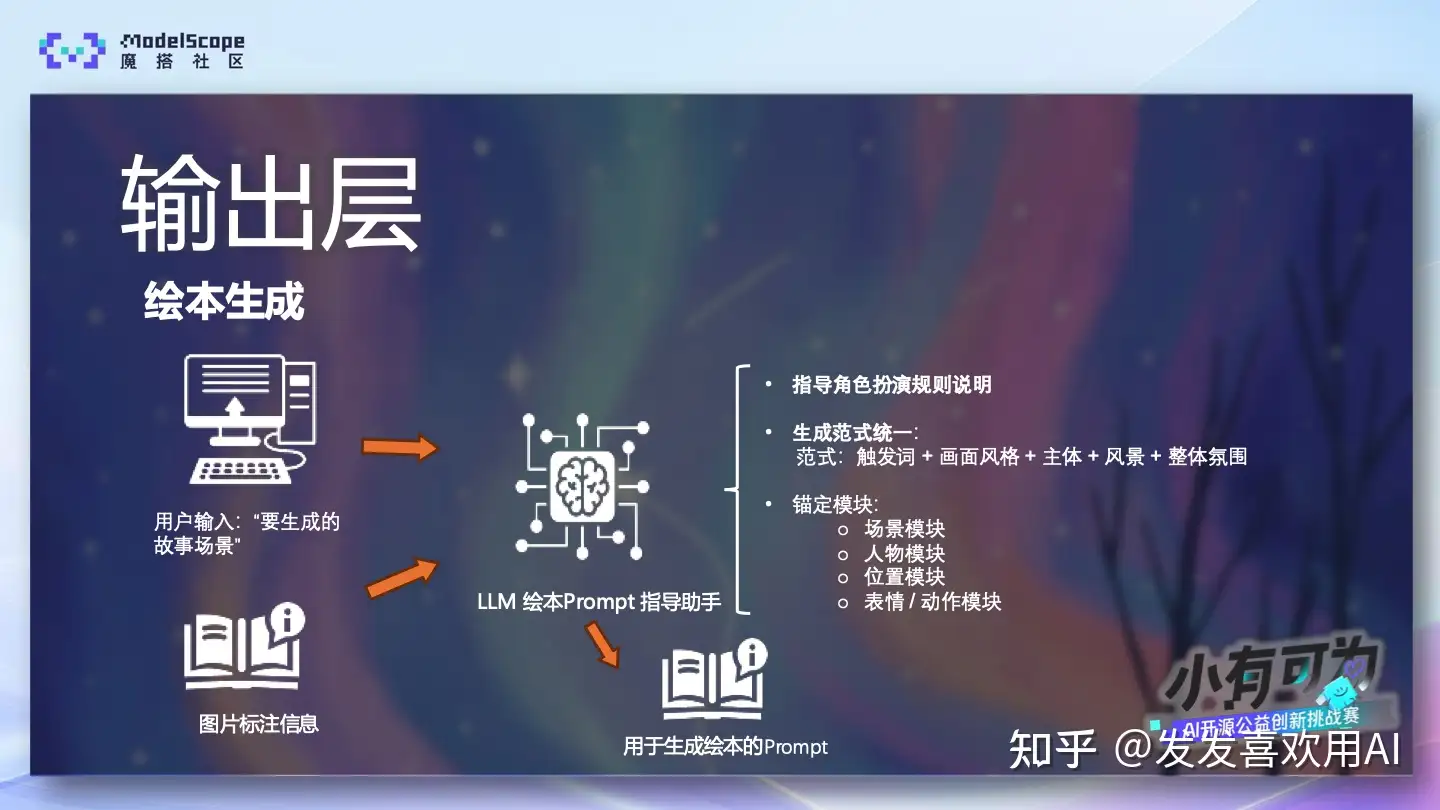
即便在系统层和输入层已经做了大量约束,在真正生成绘本的阶段,不确定性仍然可能出现。因此,我们在输出层引入了最后一层引导与约束。与前两个层级不同,输出层关注的并不是“生成什么故事”,而是一个更关键的问题:如何把用户的需求,稳定地转化为一条可控的生成指令。在这一阶段,我们引入了另一个 LLM Prompt 助手,专门用于生成“用于生成绘本的 Prompt”。
它接收两类输入:
- 要生成的故事场景描述;
- 训练阶段沉淀下来的图片文字标注信息。
在此基础上,助手并不是自由生成,而是严格遵循预设的角色扮演规则、生成范式,以及一组关键的锚定模块,来输出最终可用于绘本生成的 Prompt。
这里的 “锚定模块” 是输出层设计中的一个关键概念。如果把最终用于生成绘本的 Prompt 想象成一份结构化的施工图纸,那么模型真正生成的画面,就是按照这张图纸搭建出来的结果。这张“图纸”并不是一整块不可拆分的文本,而是由多个相对独立、但可以组合的模块构成,比如:
- 场景模块
- 人物模块
- 位置关系模块
- 表情与动作模块
不同类型的绘本,对这些模块的侧重点并不相同。有的绘本需要重点强调人物的表情和动作,有的则更依赖清晰的背景信息,有的关注人物之间的相对位置关系。而通过模块化的 Prompt 结构,我们可以只调整当前真正需要变化的部分,同时让其他模块保持稳定、不发生不必要的波动。这样一来,我们既能满足绘本在内容和功能上的差异化需求,又不会因为“多改了一点无关内容”,而引入额外的不确定性。
从系统层的整体约束,到输入层的歧义消解,再到输出层的精细控制,不确定性并不是被“消灭”的,而是被一步步限制在可控范围之内。
废话少说,放图过来
基于上面的技术方案,我们组针对不同的风格绘本制作了10+本绘本,这里我们展示4个在决赛阶段的绘本作品。
《吃饼干》
- 故事脚本:["乐乐吃完饼干,手上都是饼干屑。","妈妈说:"吃饭前后要洗手,这样才卫生。","乐乐走到洗手池边,打开水龙头,挤出洗手液,搓出泡泡。","他认真洗手指缝,用清水冲干净,再用毛巾擦干。","乐乐看着干净的小手,开心地笑了。"]
- 生成绘本

《谢谢帮助》
- 故事脚本:[ "乐乐在画画时,铅笔突然断了。", "他不知道该怎么办,有点着急。", "朵朵看到后,主动递给乐乐一支新铅笔。", "乐乐接过铅笔,看着朵朵的眼睛说:"谢谢你帮助我!"", "朵朵笑着说:"不用谢,我们是好朋友。"", "乐乐记住了当别人帮助自己时要说"谢谢"。" ]
- 生成绘本

《乐乐生气了》
- 故事脚本:[ "乐乐在拼拼图,但最后一块怎么也找不到。", "他感到很着急,脸变得通红,拳头也握紧了。", "乐乐意识到自己很生气,他想起老师教的方法。", "他走到安静角落,深呼吸三次,慢慢数到十。", "冷静下来后,他平静地问朵朵:"你能帮我找找最后一块拼图吗?"", "朵朵帮忙找到了拼图,乐乐开心地说:"谢谢你,我刚才太着急了。"" ]
- 生成绘本:

- 《画彩虹》
- 故事脚本:[ "美术课上,老师教大家画彩虹。", "乐乐用红色、橙色、黄色、绿色、蓝色、紫色的蜡笔画弧线。", "朵朵看到乐乐的彩虹,说:"真漂亮!但彩虹下面应该有东西。"", "朵朵在彩虹下画了一片绿色的草地和几朵小花。", "乐乐在草地上添了两只小鸟和一个小房子。", "他们合作完成了一幅美丽的彩虹图,老师把画贴在了教室墙上。" ]
- 生成绘本:
- 故事脚本:[ "美术课上,老师教大家画彩虹。", "乐乐用红色、橙色、黄色、绿色、蓝色、紫色的蜡笔画弧线。", "朵朵看到乐乐的彩虹,说:"真漂亮!但彩虹下面应该有东西。"", "朵朵在彩虹下画了一片绿色的草地和几朵小花。", "乐乐在草地上添了两只小鸟和一个小房子。", "他们合作完成了一幅美丽的彩虹图,老师把画贴在了教室墙上。" ]

接下来呢?
到目前为止,这套方案更多是在技术与流程层面,验证了 “如何在不确定性之中,稳定地生成可用的绘本”。而真正重要的问题在于:它是否真的能进入真实世界,被孩子、家长和特教老师使用,并产生实际价值。因此,在接下来的工作中,我们希望把关注点,从“系统是否成立”,进一步推向“它是否真的有用”。
1. 线下实践检验:回到真实的使用场景
首先需要将生成的绘本引入真实的教学与陪伴场景中。邀请孤独症儿童与一线特教老师共同参与使用这些绘本,并在实际使用过程中,收集来自真实场景的反馈。这些反馈并不局限于“画得好不好看”,而更关注一些更基础、也更关键的问题,例如:
- 孩子是否能够理解绘本所传达的内容;
- 是否愿意重复阅读与使用;
- 在教学或陪伴过程中,绘本被如何使用、是否被改编;
- 特教老师在使用过程中,是否感到负担被减轻,还是增加了新的复杂度。
这些来自真实使用场景的反馈,将帮助我们校准此前在系统设计中做出的判断,也为后续的优化提供方向。
2. 合作场景的拓展:让绘本进入更多表达与干预方式
我们也希望进一步探索绘本生成在不同合作场景中的可能性。孤独症相关的支持,并不只存在于课堂或家庭中,也存在于更丰富的社会与文化实践中。例如,国内已有一些公益机构尝试将戏剧、话剧等形式与孤独症谱系相结合,通过舞台表演与协作训练,帮助孩子进行社交练习与情绪表达。像对白社这样的实践,本身就提供了一种不同于传统教学的干预视角。我们希望未来能够与类似的公益组织展开内容层面的合作,让生成的绘本不只用于“阅读”,而是成为更广义表达与训练体系中的一部分,服务于不同的使用场景与目标。
3. 引导式生成 Agent:把工程规范,转化为用户可用的体验
最后,也是我们认为非常重要的一步,是引入引导式生成 Agent。目前,已经存在像 “追星星的 AI” 这样的绘本生成产品。它们在功能上,已经允许家长或老师选择不同的绘本风格和内容方向。但在实际使用中,一个问题依然存在:用户往往并不知道,怎样的输入,才能生成真正合适的绘本。对很多家长来说,他们并不希望学习 Prompt、理解模型差异或风格体系,他们只是想表达:“我的孩子现在需要什么样的帮助”。因此,我们希望通过引导式 Agent 的方式,利用对话式引导、选择题等形式,帮助家长或特教老师逐步明确人物、情境和关键行为信息。这个 Agent 的目标,并不是替用户做决定,而是帮助他们从模糊的“我想要什么”,逐步走向更清晰的“孩子真正需要什么”,并在这个过程中,把工程侧已经验证过的生成规范,前移到用户输入阶段。
总结
回到最初的问题,我们的方案并不是想证明 AI 能为孤独症儿童“做得更多”,而是希望确认:AI能否在不制造额外负担的前提下,将绘本制作的任务完成得更稳妥一些。对孤独症群体来说,稳定、可预期、可反复使用,往往比“更聪明”更重要。因此,在整个项目中,我们始终选择把注意力放在不确定性的拆解与收敛上,而不是单纯追求生成能力的上限。无论是二维矩阵、分层约束,还是引导式生成的设想,背后指向的都是同一个目标 - 让技术更接近真实需求,而不是反过来要求人去适应技术。我们也清楚,这并不是一个可以一次性解决的问题。但如果这套方法,能在某些具体场景中,稍微降低一点制作成本,减轻一点一线压力,或者让某个孩子更容易理解这个世界,那么它就已经具备继续被完善和使用的意义了。